【Method】Knowledge Graph Embedding
layout: post title: Knowledge Graph Embedding - A Survey of Approaches and Applications categories: Analytics —
Wang Q, Mao Z, Wang B, et al. Knowledge graph embedding: A survey of approaches and applications[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2724-2743.
- KG and KG embedding
- KG embedding with facts alone
- 3.4 Model Comparison
- 4. INCORPORATING ADDITIONAL INFORMATION
- 5. APPLICATIONS IN DOWNSTREAM TASKS
KG and KG embedding
A KG is a multi-relational graph composed of entities (nodes) and relations (different types of edges). Each edge is represented as a triple of the form (head entity, relation, tail entity), also called a fact, indicating that two entities are connected by a specific relation, e.g., (AlfredHitchcock, DirectorOf, Psycho).
Knowledge graph (KG) embedding is to embed components of a KG including entities and relations into continuous vector spaces, so as to simplify the manipulation while preserving the inherent structure of the KG.
KG embedding with facts alone
A typical KG embedding technique generally consists of three steps:
(i) representing entities and relations, The first step specifies the form in which entities and relations are represented in a continuous vector space. Entities are usually represented as vectors, Relations are typically taken as operations in the vector space, which can be represented as vectors [14], [15], matrices [16], [18], tensors [19], multivari- ate Gaussian distributions [45], or even mixtures of Gaus- sians [46].
(ii) defining a scoring function, and
(iii) learning entity and relation representations.
We roughly categorize such embedding techniques into two groups: translational distance models and semantic match- ing models. The former use distance-based scoring functions, and the latter similarity-based ones.
Translational Distance Models

TransEand Its Extensions
TransE. TransE [14] is the most representative translational distance model. It represents both entities and relations as vectors in the same space, say Rd. Given a fact ðh; r; tÞ, the relation is interpreted as a translation vector r so that the embedded entities h and t can be connected by r with low error, i.e., h þ r ? t when ðh; r; tÞ holds.
TransH
TransR
TransD
Gaussian Embeddings
Some recent works take into account their uncertainties, and model them as random variables [45], [46]. KG2E [45] represents entities and relations as random vectors drawn from multi- variate Gaussian distributions.
Other Distance Models
Unstructured model (UM) [56] is a naive version of TransE by setting all r ¼ 0, leading to a scoring function.
Semantic Matching Models

RESCAL and Its Extensions
Matching with Neural Networks
Model Training
Training under Open World Assumption
Training under Closed World Assumption
3.4 Model Comparison
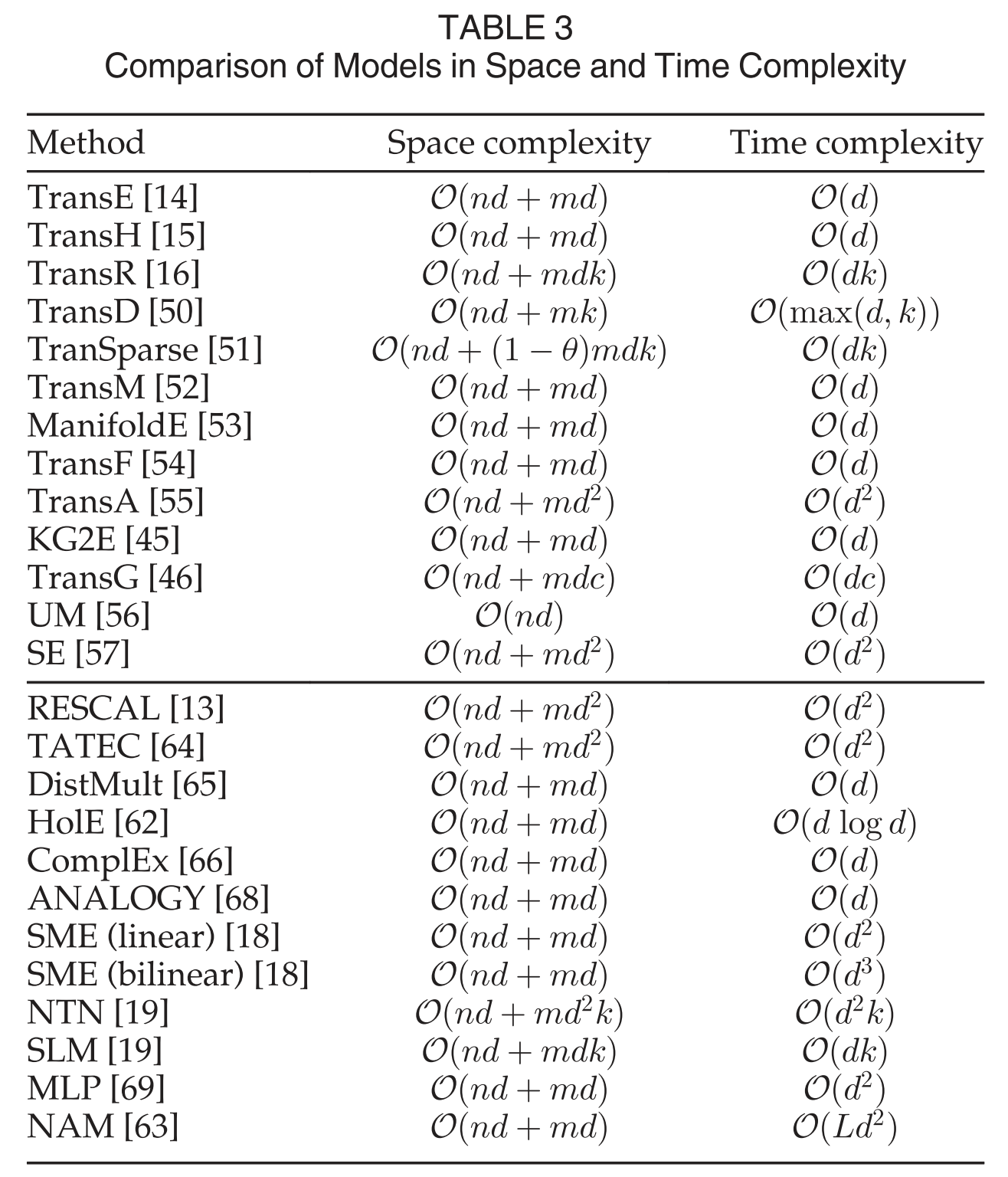
3.5 Other Approaches
4. INCORPORATING ADDITIONAL INFORMATION
The methods introduced so far conduct the embedding task using only facts observed in the KG. In fact, there is a wide variety of additional information that can be incorporated to further improve the task, e.g., entity types, relation paths, textual descriptions, as well as logical rules.
4.1 Entity Types
4.2 Relation Paths
4.3 Textual Descriptions
4.4 Logical Rules
4.5 Other Information
Entity Attributes
Temporal Information
Graph Structures
5. APPLICATIONS IN DOWNSTREAM TASKS
5.1 In-KG Applications
5.1.1 Link Prediction
5.1.2 Triple Classification
Triple classification consists in verifying whether an unseen triple fact ðh; r; tÞ is true or not
5.1.3 Entity Classification
5.1.4 Entity Resolution
Entity resolution consists in verifying whether two entities refer to the same object.