【Method】Topic Model(一)LSA
原理
所有主题模型都基于相同的基本假设:
- 每个文档包含多个主题;
- 每个主题包含多个关键词。
换句话说,主题模型围绕着以下观点构建:实际上,文档的语义由一些我们所忽视的隐变量或“潜”变量管理。因此,主题模型的目标就是揭示这些潜在变量——也就是主题,正是它们塑造了我们文档和语料库的含义。
LSA
潜在语义分析(LSA)是主题建模的基础技术之一。其核心思想是把我们所拥有的“文档-术语”矩阵分解成相互独立的“文档-主题”矩阵和“主题-术语”矩阵。
第一步是生成“文档-术语”矩阵。如果在词汇表中给出m个文档和n个单词,我们可以构造一个m×n的矩阵A,其中每行代表一个文档,每列代表一个单词。在LSA的最简单版本中,每一个条目可以简单地是第j个单词在第i个文档中出现次数的原始计数。
然而,在实际操作中,原始计数的效果不是很好,因为它们无法考虑文档中每个词的权重。例如,比起”test”来说,”nuclear”这个单词也许更能指出给定文章的主题。因此,LSA模型通常用TF-IDF得分代替“文档-术语”矩阵中的原始计数。TF-IDF,即词频-逆文本频率指数,为文档i中的术语j分配了相应的权重,如下:
\[w_{i,j} = tf-idf_{i,j}\]直观地说,术语出现在文档中的频率越高,则其权重越大;同时,术语在语料库中出现的频率越低,其权重越大。
一旦拥有“文档-术语”矩阵A,我们就可以开始思考潜在主题。问题在于:A极有可能非常稀疏、噪声很大,并且在很多维度上非常冗余。因此,为了找出能捕捉单词和文档关系的少数潜在主题,我们希望能降低矩阵A的维度。
这种降维可以使用截断SVD来执行。SVD,即奇异值分解,是线性代数中的一种技术。该技术将任意矩阵M分解为三个独立矩阵的乘积:\(M=U*S *V\),其中S是矩阵M奇异值的对角矩阵。很大程度上,截断SVD的降维方式是:选择奇异值中最大的t个数,且只保留矩阵U和V的前t列。在这种情况下,t是一个超参数,我们可以根据想要查找的主题数量进行选择和调整。
直观来说,截断SVD可以看做只保留我们变化空间中最重要的t维。
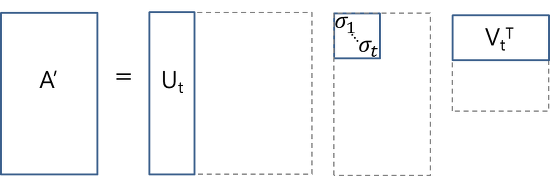
在这种情况下,\(U \in R^{(m \times t)}\) 是我们的“文档-主题”矩阵,而\(V \in R^{(n \times t)}\)则成为我们“主题-术语”矩阵。在矩阵U和V中,每一列对应于我们t个主题当中的一个。在U中,行表示按主题表达的文档向量;在V中,行代表按主题表达的术语向量。
通过这些文档向量和术语向量,现在我们可以轻松应用余弦相似度等度量来评估以下指标:
- 不同文档的相似度
- 不同单词的相似度
- 术语(或”queries”)与文档的相似度(当我们想要检索与查询最相关段落,即进行信息检索时,这一点非常有用)
LSA 方法快速且高效,但它也有一些主要缺点:
- 缺乏可解释的嵌入(我们并不知道主题是什么,其成分可能积极或消极,这一点是随机的)
- 需要大量的文件和词汇来获得准确的结果
- 表征效率低