【Method】Topic Model(二)pLSA
原理
概率隐性语义分析(Probabilistic latent semantic analysis, pLSA)采取概率方法替代LSA中的SVD以解决问题。
其核心思想是找到一个潜在主题的概率模型,该模型可以生成我们在“文档-术语”矩阵中观察到的数据。特别是,我们需要个模型P(D,W),使得对于任何文档d和单词w,P(d,w)能对应于“文档-术语”矩阵中的那个条目。
让我们回想主题模型的基本假设:每个文档由多个主题组成,每个主题由多个单词组成。则在pLSA中
- 给定文档d,主题z以\(P(z \mid d)\)的概率出行在该文档中;
- 给定主题d,单词w以\(P(w \mid z)\)的概率从主题z中提取出来。20
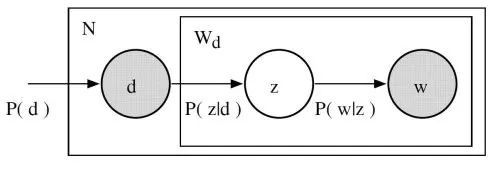
从形式上看,一个给定的文档和单词同时出行的联合概率是:
直观来说,等式右边告诉我们理解某个文档的可能性有多大;然后,根据该文档主题的分布情况,在该文档中找到某个单词的可能性有多大。
在这种情况下,P(D)、\(P(Z \mid D)\)、和\(P(W \mid Z)\)是我们模型的参数。P(D)可以直接由我们的语料库确定。\(P(Z \mid D)\)和\(P(W \mid Z)\)利用了多项式分布建模,并且可以使用期望最大化算法(EM)进行训练。EM无需进行算法的完整数学处理,而是一种基于未观测潜变量(此处指主题)的模型找到最可能的参数估计的方法。
有趣的是,P(D,W)可以利用不同的3个参数等效地参数化:
可以通过将模型看作一个生成过程来理解这种等价性。在第一个参数化过程中,我们从概率为P(d)的文档开始,然后用\(P(z \mid d)\)生成主题,最后用\(P(w \mid z)\)生成单词。而在上述这个参数化过程中,我们从P(z)开始,再用\(P(d \mid z)\)和\(P(w \mid z)\)单独生成文档。
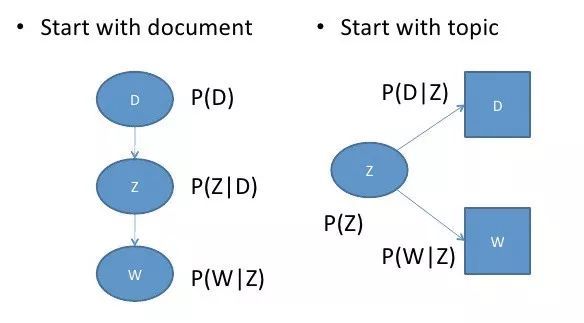
这个新参数化方法非常有趣,因为我们可以发现pLSA模型和LSA模型之间存在一个直接的平行对应关系:
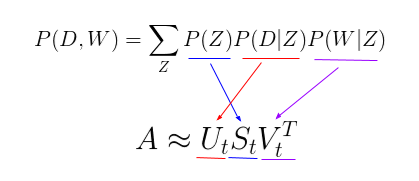
其中,主题P(Z)的概率对应于奇异主题概率的对角矩阵,给定主题\(P(D \mid Z)\)的文档概率对应于“文档-主题”矩阵U,给定主题\(P(W \mid Z)\)的单词概率对应于”术语-主题“矩阵V。
这说明了尽管pLSA看起来与LSA差异很大、且处理问题的方法完全不同,但实际上pLSA只是在LSA的基础上添加了对主题和词汇的概率处理罢了。pLSA是一个更加灵活的模型,但仍然存在一些问题,尤其表现为:
- 因为我们没有参数来给P(D)建模,所以不知道如何为新文档分配概率;
- pLSA的参数数量随着我们拥有的文档数线性增长,因此容易出现过拟合问题。
相比于LDA模型里涉及先验分布,pLSA模型相对简单:观测变量为文档\(d_m \in D\)(文档集共有M篇文档)、词\(w_n \in W\)(设词汇表共有V个互不相同的词),隐变量为主题\(z_k \in Z\)(共K个主题)。在给定文档集后,我们可以得到一个词-文档共现矩阵,每个元素\(n(d_m, w_n)\)表示的是词\(w_n\)在文档\(d_m\)中的词频。也就是说,pLSA模型也是基于词-文档共现矩阵的,不考虑词序。
pLSA模型通过以下过程来生成文档(记号里全部省去了对参数的依赖):
(1) 以概率\(P(d_m)\)来选择一篇文档\(d_m\);
(2) 以概率\(P(z_k \mid d_m)\)得到一个主题\(z_k\);
(3) 以概率\(P(w_n \mid z_k)\)生成一个词\(w_n\)。
概率图模型如下:
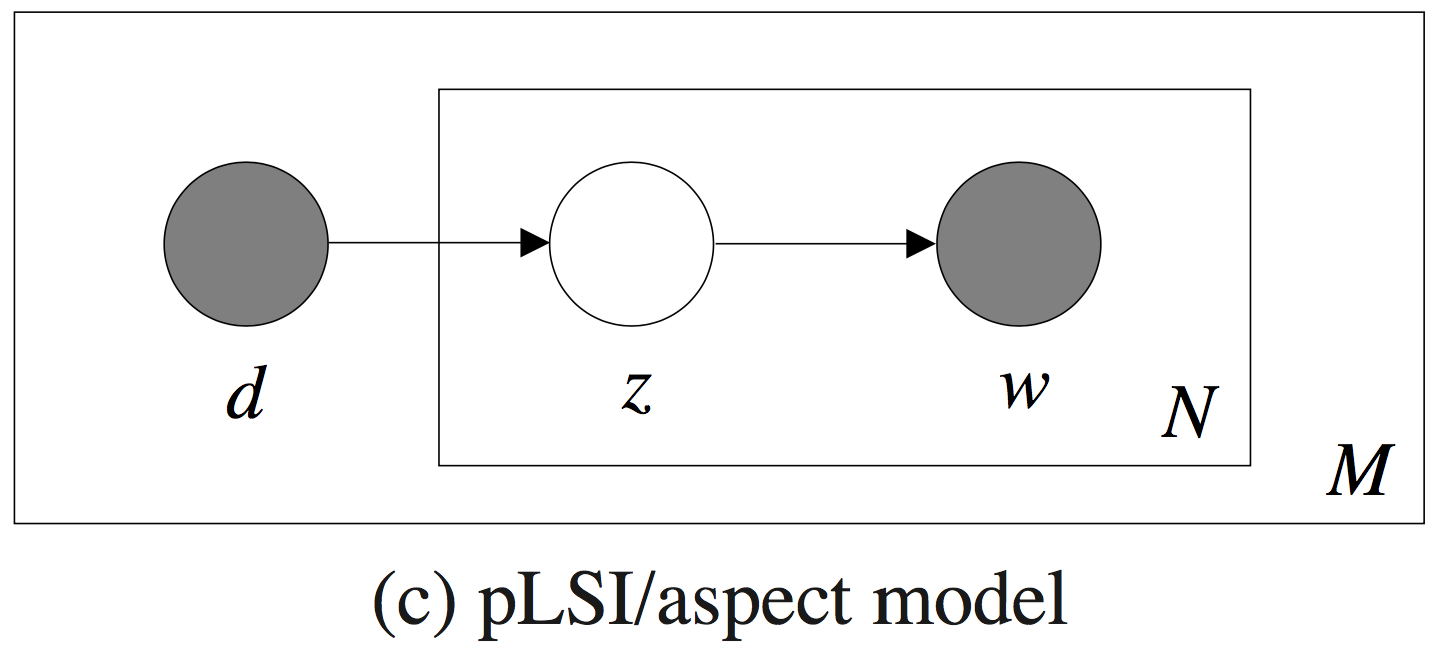
图里的浅色节点代表不可观测的隐变量,方框是指变量重复(plate notation),内部方框表示的是词库大小为N,外部方框表示的是文档集共M篇文档。pLSA模型的参数\(\theta\)显而易见就是:\(K \times M\)个\(P(z_k \mid d_m)\)、\(N \times K\)个\(P(w_n \mid z_k)\)。\(P(z_k \mid d_m)\)表征的是给定文档在各个主题下的分布情况,文档在全部主题上服从多项式分布(共M个);\(P(w_n \mid z_k)\)则表征给定主题的词语分布情况,主题在全部词语上服从多项式(共K个)。
联合分布
拿到贝叶斯网络当然先要看联合分布。这个贝叶斯网络表达的是如下的联合分布:
\[P(d_m, z_k,, w_n) = P(d_m)P(z_k \mid d_m)P(w_n \mid z_k)\] \[P(d_m, w_n) = P(d_m)P(w_n \mid d_m)\]假设有一篇文档为\(\overrightarrow{w} = (w_1, w_2, ...,w_N)\),生成它的概率就是
\[P(\overrightarrow{w} \mid d_m) = \prod_{n=1}^N P(w_n \mid d_m)\]我们看一下\(P(w_n \mid d_m)\)的表达式。如果不考虑随机变量之间的条件独立性的话,有
\[P(w_n \mid d_m) = \sum_k P(z_k \mid d_m)P(w_n \mid z_k, d_m)\]但是观察图模型中的d、z、w可以知道,它们三个是有向图模型里非常典型的head-to-tail的情况:当z已知时,d和w条件独立,也就是
\[P(w_n \mid z_k, d_m) = P(w_n \mid z_k)\]进而有
\[P(w_n \mid d_m) = \sum_k P(z_k \mid d_m)P(w_n \mid z_k)\]所以最终的联合分布表达式为
\[P(d_m, w_n) = P(d_m) \sum_k P(z_k \mid d_m)P(w_n \mid z_k)\]似然函数
这样的话,我们要做的事就是从文档集里估计出上面的参数。pLSA是频率学派的方法,将模型参数看作具体值,而不是有先验的随机变量。所以,考虑最大化对数似然函数:
\[\begin{align} L(\theta) &= ln \prod_{m=1}^M \prod_{n=1}^N P(d_m,w_n)^{n(d_m,w_n)} \\ &= \sum_m \sum_n n(d_m, w_n) ln P(d_m, w_n) \\ &= \sum_m \sum_n n(d_m, w_n) (ln P(d_m) + ln P(w_n \mid d_m)) \\ &= \sum_m \sum_n n(d_m, w_n) ln P(w_n \mid d_m) + \sum_m \sum_n n(d_m, w_n) ln P(d_m) \\ \end{align}\]其中\(n(d_m, w_n)\)是\(w_n\)出现在文档\(d_m\)中的次数。出现的次数是确定的,文档的概率也是已有的,对求取极大值点无影响,所以第二项可以直接去掉,那么不妨直接记:
\[\begin{align} L(\theta) &= \sum_m \sum_n n(d_m, w_n) ln P(w_n \mid d_m) \\ &= \sum_m \sum_n n(d_m, w_n) ln [\sum_k P(z_k \mid d_m)P(w_n \mid z_k)] \\ \end{align}\]参数估计:EM算法迭代求解
由于参数全部在求和号里被外层的log套住,所以很难直接求偏导数估计参数。到了这里,就轮到EM算法闪亮登场了。
- E步,求期望
对于pLSA模型来说,Q函数的形式为
\[\begin{align} Q(\theta; \theta_t) &= \sum_m \sum_n n(d_m,w_n) E_{z_k \mid w_n,d_m;\theta_t}[ln P(w_n, z_k \mid d_m)] \\ &= \sum_m \sum_n n(d_m,w_n) \sum_k P(z_k \mid w_n, d_m; \theta_t) ln P(w_n, z_k \mid d_m) \\ \end{align}\](1) 联合概率\(P(w_n,z_k \mid d_m)\)求解:
\[P(w_n, z_k \mid d_m) = P(z_k \mid d_m)P(w_n \mid z_k,d_m) = P(z_k \mid d_m) = P(z_k \mid d_m)P(w_n \mid z_k)\](2) \(P(z_k \mid w_n, d_m; \theta_t)\)的求解:
所谓的\(\theta_t\)实际上就是上一步迭代的全部\(K \times M\)个\(P(z_k \mid d_m)\)和\(V \times K\)个\(P(w_n \mid z_k)\)。
\[\begin{align} P(z_k \mid w_n, d_m; \theta_t) &= \frac{P_t(z_k, w_n, d_m)}{P_t(w_n, d_m)} = \frac{P_t(d_m)P_t(z_k \mid d_m)P_t(w_n \mid z_k)}{P_t(d_m)P_t(w_n \mid d_m)} \\ &= \frac{P_t(z_k \mid d_m)P_t(w_n \mid z_k)}{P_t(w_n \mid d_m)} = \frac{P_t(z_k \mid d_m)P_t(w_n \mid z_k)}{\sum_j P_t(z_j \mid d_m)P_t(w_n \mid z_j)} \\ \end{align}\]基于以上两个结果,得到Q函数的形式为
\[\begin{align} Q(\theta; \theta_t) &= \sum_m \sum_n n(d_m, w_n) \sum_k P(z_k \mid w_n, d_m; \theta_t)(ln P(z_k \mid d_m) + ln P(w_n \mid z_k)) \\ &= \sum_m \sum_n n(d_m, w_n) \sum_k \frac{P_t(z_k \mid d_m)P_t(w_n \mid z_k)}{\sum_j P_t(z_j \mid d_m)P_t(w_n \mid z_j)} (ln P(z_k \mid d_m) + ln P(w_n \mid z_k)) \\ \end{align}\]终于,在这个形式里面,除了\(\theta\)(全部\(K \times M\)个\(P(z_k \mid d_m)\)和\(V \times K\)个\(P(w_n \mid z_k)\)),已经全部为已知量。
- M步,求极大值
剩下的工作就是
\[\theta_{t+1} = arg max_\theta Q(\theta; \theta_t)\]问题将会被概括为如下的约束最优化问题:
目标函数:\(max_\theta Q(\theta; \theta_t)\); 约束:\(\sum_n P(w_n \mid z_k) = 1, \sum_k P(z_k \mid d_m) = 1\)
使用Lagrange乘数法,得到Lagrange函数为
\[Q(\theta; \theta_t) + \sum_k \tau_k (1- \sum_n P(w_n \mid z_k) ) + \sum_m \rho_m(1- \sum_k P(z_k \mid d_m))\]令其对参数的偏导数等于零,得到\(K \times M + V \times K\)个方程,这些方程的解就是最优化问题的解:
\[\frac{\partial}{\partial P(w_n \mid _k)} = \frac{\sum_m n(d_m, w_n) P(z_k \mid w_n, d_m; \theta_t)}{P(w_n \mid z_k)} - \tau_k = 0, 1 \leq n \leq V, 1 \leq k \leq K\] \[\frac{\partial}{\partial P(z_k \mid d_m)} = \frac{\sum_n n(d_m, w_n) P(z_k \mid w_n, d_m; \theta_t)}{P(z_k \mid d_m))} - \rho_m = 0, 1 \leq m \leq V, 1 \leq k \leq K\]方程的解为
\[P(w_n \mid z_k) = \frac{\sum_m n(d_m,w_n) P(z_k \mid w_n, d_m; \theta_t)}{\tau_k}\] \[P(z_k \mid d_m) = \frac{\sum_m n(d_m,w_n) P(z_k \mid w_n, d_m; \theta_t)}{\rho_m}\]注意到两个约束条件,即
\[\sum_n \frac{\sum_m n(d_m, w_n)P(z_k \mid w_n, d_m; \theta_t)}{\tau_k} = 1\] \[\sum_k \frac{\sum_m n(d_m,w_n) P(z_k \mid w_n, d_m; \theta_t)}{\rho_m} = 1\]从中可求得\(\tau_k, \rho_m\),所以方程的解为
\[P_{t+1}(w_n \mid z_k) = \frac{\sum_m n(d_m, w_n) P(z_k \mid w_n, d_m; \theta_t)}{\sum_n \sum_m n(d_m, w_n) P(z_k \mid w_n, d_m; \theta_t)}\] \[P_{t+1}(z_k \mid d_m) = \frac{\sum_n n(d_m, w_n) P(z_k \mid w_n, d_m; \theta_t)}{\sum_k \sum_n n(d_m, w_n) P(z_k \mid w_n, d_m; \theta_t)}\]当模型参数全部估计好后,便得到了完整的pLSA模型。上面的迭代过程很明显是一个频数估计(极大似然估计)的形式,意义很明确。模型使用EM算法进行参数估计时往往都会推导出这样的结果,例如HMM。
pLSA模型小结
上面一系列公式因为总是在前面挂着两个求和号,所以看上去貌似挺热闹,其实它相比于朴素的三硬币模型的推导过程来说,无非就是多了作为条件出现的随机变量d,其余地方没有本质区别。
不难看出来,pLSA模型需要顾及的参数数量是和训练文档集的大小是有关系的——因为有\(P(z_k \mid d_m)\)。显然,在训练集上训练出来的这组参数无法应用于训练文档以外的测试文档。
作为频率学派的模型,pLSA模型中的参数被视作具体的值,也就谈不上什么先验。如果在真实应用场景中,我们对参数事先有一些先验知识,那么就需要使用贝叶斯估计来做参数估计。此时就会用到LDA模型。